Kubernetes
Main components
- Nodes & Pods
- Service
- Ingress
- ConfigMap
- Secret
- Deployment
- DeamonSet
- StatefulSet
Node
- Une Node est une machine, physique ou virtuelle.
- La plus petite unité de Kube est un Pod. Les containers sont dans les Pods.
- Abastraction over container. Le Pod va donc créer une couche d'abstraction, un environnement, on va ensuite extraire le runtimes et les différentes technologies de de conteneurs pour les manipuler avec Kubernetes par la suite.
**Nous n'interagirons qu'avec la couche de Pod de Kubernetes. **
On utilise en général une seule application par POD (un conteneurs), qui lui même pourrait être lié à une autre POD (de BDD par exemple). Un peu comme avec Docker.
Les conteneurs sont une abstraction au niveau de la couche d'application qui regroupe le code et les dépendances. Plusieurs conteneurs peuvent s'exécuter sur la même machine et partager le noyau du système d'exploitation avec d'autres conteneurs, chacun s'exécutant en tant que processus isolés dans l'espace utilisateur. Les conteneurs occupent moins d'espace que les machines virtuelles (les images de conteneur ont généralement une taille de plusieurs dizaines de Mo), peuvent gérer plus d'applications et nécessitent moins de machines virtuelles et de systèmes d'exploitation.
Chaque POD aura sa propre IP interne au niveau du réseau. On peux communiquer avec l'IP mais en cas de renouvellement d'un Pod, une nouvelle IP pourrait être attribué. Ce n'est donc pas pratique et pas fiable.
C'est la qu'intervienne les Services.
Exemple de "main container" vs "side-car container" dans un projet :
J'ai un pod avec une application Kibana à l'intérieur (le main container) et afin de le sécuriser, il y a une deuxième application keycloak-gatekeeper (side-car container") déployée à l'intérieur du pod qui authentifie la demande contre keycloak avant qu'elle n'atteigne l'application principale, sécurisée.
"sidecar" est un terme officiel. "main", est une appelation plus générale.
Les pods contiennent principalement 1 conteneur, selon qui ? - Selon les projets et après recherches sur les meilleures pratiques d'autres projets. La majorité des conteneurs n'ont pas besoin de conteneurs/conteneurs étroitement couplés avec des cycles de vie synchronisés. Gardez en tête que fonction de l'organisation, rien n'est gravé dans la docs.
Infos : Container Communication inside the Pod
Les Services
Les service est une adresse IP statique permanent à ajouter à chaque Pod, et chaque Pod aura son propre service et son cycle de vie. Donc si un Pod tombe, le service réassignera l'IP originel.
Si nous voulons rendre accessible un Pod avec un mappage de port comme avec docker, il faudra créé un service externe qui ouvrira la communication a partir de sources externe, mais par ex une BDD qui est non publique, ne sera pas forcément accessible. Par exemple, après création d'un service externe, on pourrait accéder à notre app avec une adresse de type http://172.16.20.51:8080 ou http://myapp.com:8080
C'est utiles à des fins de tests mais il serait préférable pour notre application d'être accessible plutôt avec un nom de domaine sécurisé directement type https://myapp.com. Pour cela nous utiliserons les INGRESS.
Ingress
Ingress est un composant de Kube qui viendra au dessus du POD et des Services. Donc à l'appel d'une appli d'un Pod, au lieu de contacter le service directement, c'est le Ingress qui sera appelé, puis il forwardera la demande au Service.

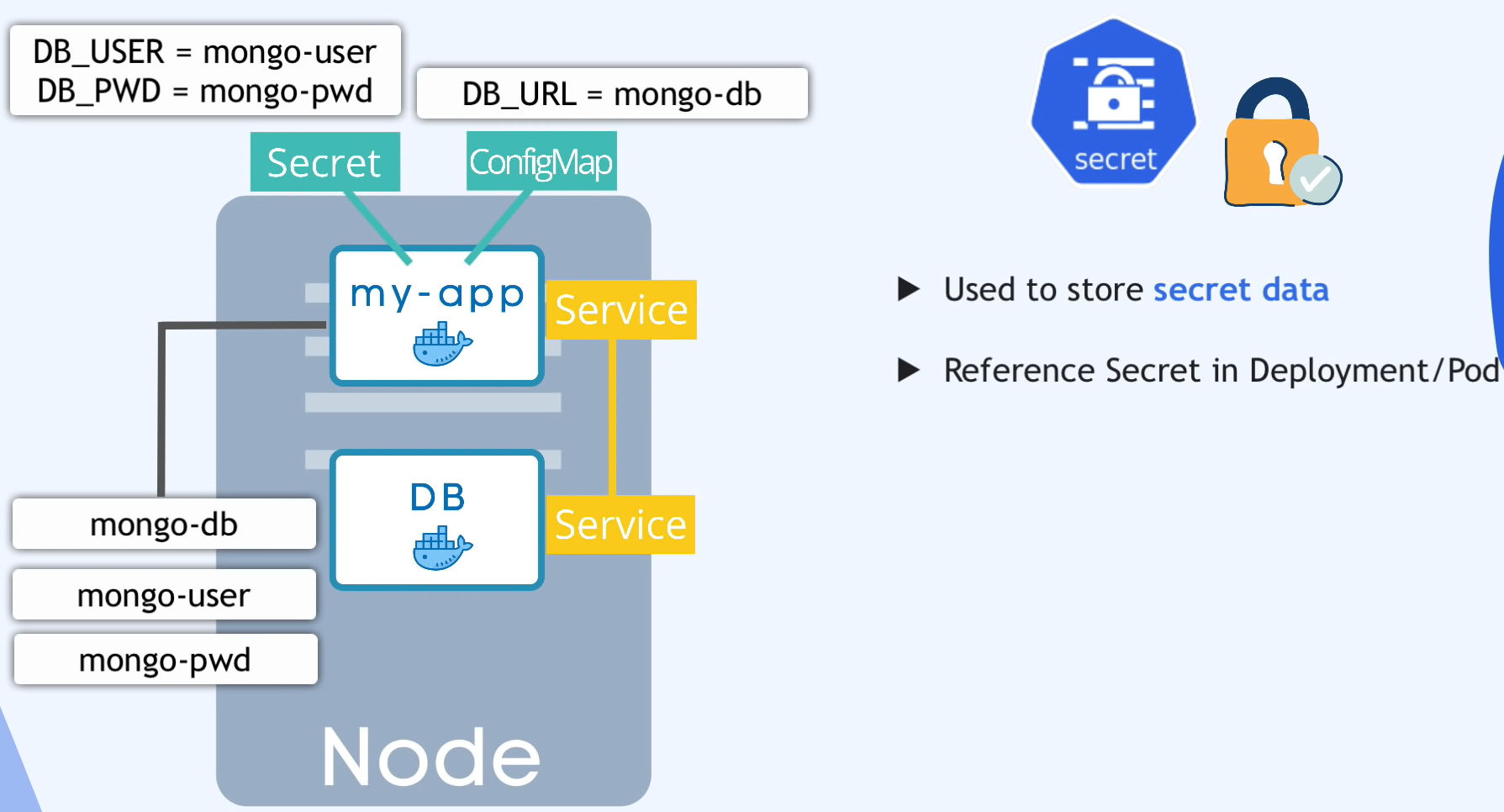
ConfigMap & Secret
Retenons que les Pods communiquent entre eux via les Services. Disons que notre Pod utilise un conteneur MongoDB comme base de donnée. La BDD est généralement build dans l'image, et à chaque modification, il faudrait refaire une image par exemple. Pas très pratique si nous avons besoin de changer une simple URL par exemple.
ConfigMap
Les ConfigMap et les secrets sont des ressources dans Kubernetes qui permettent de stocker et de gérer des données sensibles et non sensibles.
Les ConfigMap sont utilisés pour stocker des données de configuration qui peuvent être utilisées par des conteneurs dans un Pod. Par exemple, vous pouvez stocker des informations telles que les paramètres d'application, les URL de service externe, etc. Les ConfigMap sont des objets simples et peuvent être créés à partir de fichiers YAML ou de données en ligne de commande. Voici un exemple de création de ConfigMap à partir d'un fichier YAML :
yaml apiVersion: v1 kind: ConfigMap metadata: name: example-config data: example.property: value
Les Secret
Les secrets sont utilisés pour stocker des données sensibles telles que les mots de passe, les certificats SSL, etc. Les secrets sont stockés de manière chiffrée dans le cluster et peuvent être utilisés par les conteneurs dans les pods pour s'authentifier avec des services externes. Les éléments seront stockés en base64.
Voici un exemple de création de secret à partir de données en ligne de commande :
kubectl create secret generic example-secret --from-literal=example.property=value
Lorsqu'un pod est créé, vous pouvez faire référence à un ConfigMap ou à un secret en utilisant un objet de volume de type configMap ou secret. Le système de fichiers du conteneur peut alors accéder aux données stockées dans le ConfigMap ou le secret. Par exemple, vous pouvez définir un volume de type secret qui expose les données du secret en tant que fichier dans le conteneur :
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: example-image
volumeMounts:
- name: example-secret
mountPath: /etc/secret-volume
readOnly: true
volumes:
- name: example-secret
secret:
secretName: example-secret
Les secrets Kubernetes sont, par défaut, stockés non chiffrés dans le magasin de données sous-jacent du serveur d'API (etcd). Toute personne ayant accès à l'API peut récupérer ou modifier un secret, de même que toute personne ayant accès à etcd. De plus, toute personne autorisée à créer un pod dans un espace de noms peut utiliser cet accès pour lire n'importe quel secret dans cet espace de noms ; cela inclut l'accès indirect, comme la possibilité de créer un déploiement.
Afin d'utiliser Secrets en toute sécurité, suivez au moins les étapes suivantes :
- Activez le chiffrement au repos pour les secrets.
- Activez ou configurez les règles RBAC avec un accès au moindre privilège aux secrets.
- Limitez l'accès secret à des conteneurs spécifiques.
- Envisagez d'utiliser des fournisseurs externes de magasins secrets .
Pour plus d'informations sur la gestion et l'amélioration de la sécurité de vos secrets, consultez Bonnes pratiques pour les secrets Kubernetes .
Il est existe donc des outils tiers pour le chiffrement.
Exemple
Nous pouvons également utiliser un objet ConfigMap pour stocker des données de configuration qui ne sont pas sensibles à la sécurité. Par exemple, nous pouvons stocker les paramètres d'application dans un ConfigMap.
Voici un exemple de définition de ConfigMap.
Dans ce ConfigMap, nous définissons deux clés,
application-setting-1etapplication-setting-2, qui contiennent respectivement les valeursvalue1etvalue2.En utilisant ces deux objets, nous pouvons séparer les données sensibles et les données de configuration, ce qui nous permet de gérer ces données de manière plus efficace et sécurisée.
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
application-setting-1: value1
application-setting-2: value2
Supposons que nous avons une entreprise fictive appelée "Mon entreprise" qui développe une application web appelée "Mon application". Cette application a besoin d'accéder à une base de données pour fonctionner correctement, mais nous ne voulons pas inclure les informations de connexion de la base de données directement dans le code de l'application. Au lieu de cela, nous pouvons utiliser un objet Kubernetes Secret pour stocker les informations de connexion de la base de données.
Voici un exemple de définition de secret.
Ce secret définit deux clés,
database-usernameetdatabase-password, qui contiennent respectivement les valeurs chiffrées deadminetpassword. Les valeurs sont codées en base64.yaml
apiVersion: v1
kind: Secret
metadata:
name: db-secret
type: Opaque
data:
database-username: YWRtaW4=
database-password: cGFzc3dvcmQ=
Volumes
De la même manière qu'avec Docker, il est possible de mapper des volumes locaux vers des dossier dans un pod/conteneur. Cela peut être un volume local comme un volume distant, sur un serveur de stockage dédié ou via une solution cloud type S3 par exemple.
Le but est de rendre les données persistante et de ne rien perdre en cas de manipulation, suppression, déploiement etc.. es pods.
Exemple
Imaginons que nous avons une entreprise appelée "ACME Inc." qui développe une application Web appelée "Super App". Cette application a besoin d'accéder à des fichiers de configuration spécifiques pour fonctionner correctement. Pour gérer ces fichiers de configuration, ACME Inc. décide d'utiliser ConfigMaps dans Kubernetes.
Voici comment cela pourrait être implémenté dans Kubernetes :
-
Créer un fichier de configuration appelé "config.properties" avec les paramètres nécessaires pour "Super App".
-
Créer un ConfigMap à partir de ce fichier de configuration :
kubectl create configmap super-app-config --from-file=config.properties
- Déployer "Super App" en utilisant ce ConfigMap pour fournir les paramètres de configuration :
apiVersion: apps/v1
kind: Deployment
metadata:
name: super-app
spec:
replicas: 1
selector:
matchLabels:
app: super-app
template:
metadata:
labels:
app: super-app
spec:
containers:
- name: super-app
image: super-app:1.0
ports:
- containerPort: 8080
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: super-app-config
Ainsi, le ConfigMap est monté en tant que volume dans le conteneur de l'application et les paramètres de configuration sont accessibles à partir de ce volume. De cette manière, ACME Inc. peut facilement gérer et mettre à jour les paramètres de configuration pour "Super App" sans avoir à redéployer toute l'application.
Cet exemple montre comment les ConfigMaps peuvent être utilisés pour gérer les fichiers de configuration dans Kubernetes. De manière similaire, les Secrets peuvent être utilisés pour stocker et gérer des informations sensibles telles que les mots de passe, les clés API, etc. Les Secrets peuvent également être montés en tant que volumes dans les conteneurs, ou utilisés directement dans les définitions de pods.
Deployment & StatefulSet
Deployment
Maintenant, supposons que tout fonctionne parfaitement et que les utilisateurs peuvent accéder à notre application via un navigateur. Dans ce cas de figure, si un des pods de l'application tombe en panne ou si nous devons redémarrer le pod parce que nous avons créé une nouvelle image de conteneur, cela entraînerait une interruption de service pendant laquelle les utilisateurs ne pourraient pas accéder à notre application, ce qui est évidemment très mauvais si cela se produit en production.
C'est là qu'interviennent les avantages des systèmes distribués et des conteneurs. Au lieu de compter uniquement sur une partie de l'application et une partie de la base de données, nous les répliquons sur plusieurs serveurs. Ainsi, nous aurions un autre nœud où une réplique ou un clone de notre application tournerait également et serait également connecté au service.
Rappelez-vous que le service est comme une adresse IP persistante avec un nom de domaine DNS. Cela signifie que vous n'avez pas à ajuster constamment le point de terminaison lorsqu'un pod meurt. Le service est également un équilibreur de charge, ce qui signifie qu'il attrapera la demande et la transmettra au composant qui est le moins occupé.
Afin de créer une deuxième réplique du pod de notre application, vous ne créerez pas un deuxième pod, mais vous définirez un blueprint pour un pod de notre application et spécifierez combien de répliques de ce pod vous souhaitez exécuter.
Ce composant ou ce blueprint est appelé deployment, qui est un autre composant de Kubernetes. En pratique, vous travaillerez plutôt avec les déploiements et non avec les pods, car vous pouvez spécifier combien de répliques sont nécessaires et également redimensionner le nombre de répliques de pods.
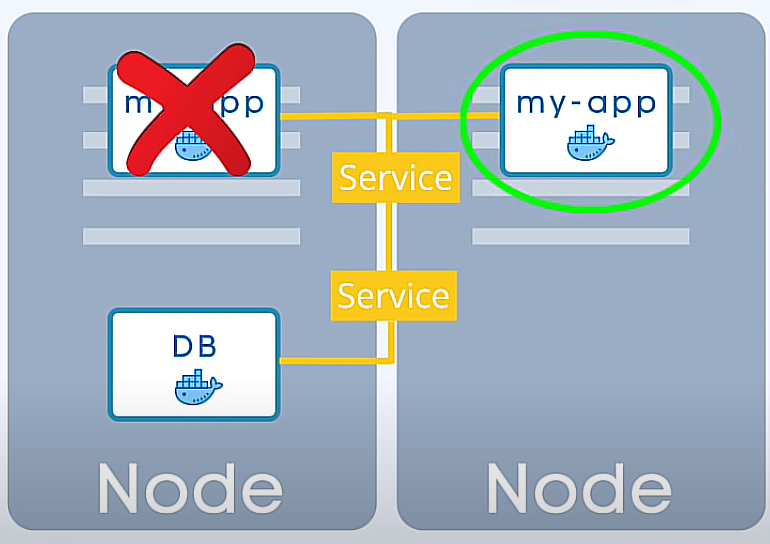
Si l'un des pods de l'application tombe en panne, le service transmettra les requêtes à un autre pod, de sorte que l'application sera toujours accessible pour les utilisateurs. Vous vous demandez probablement ce qui se passe pour le pod de la base de données, car si le pod de la base de données tombe en panne, l'application ne serait également pas accessible. Nous avons donc également besoin d'une réplique de la base de données. Cependant, nous ne pouvons pas répliquer la base de données à l'aide d'un déploiement, car la base de données a un "state", qui sont ses données. Ce qui signifie qu'elle doit conserver l'état actuel de toutes les données. Pour garantir la disponibilité de la base de données, nous utilisons un service de base de données de cluster, qui peut être déployé sur plusieurs nœuds et maintiendra une copie synchronisée des données sur plusieurs instances. En cas de panne d'un nœud, le service de cluster de base de données s'assurera que les données soient transférées à un autre nœud afin que la base de données soit toujours disponible pour les utilisateurs. De cette manière, nous pouvons garantir la disponibilité de notre application, même en cas de panne d'un pod ou d'un nœud.
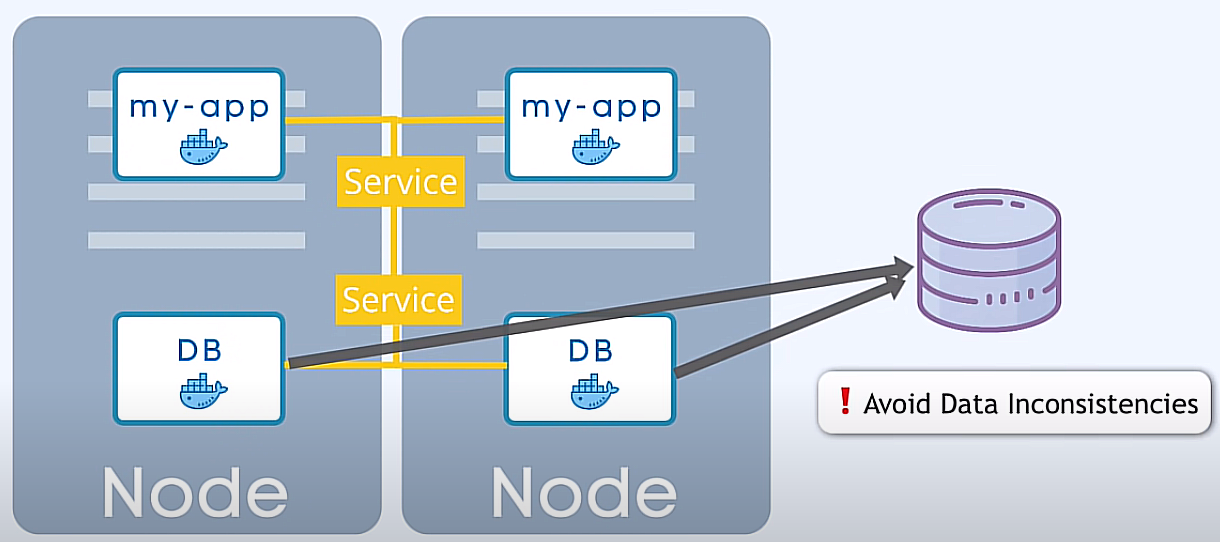
StatefulSet
Ce mécanisme, en plus des fonctionnalités de réplication, est offert par un autre composant appelé StatefulSet.
Il est conçu spécifiquement pour les applications comme les bases de données, telles que MySQL, MongoDB, Elasticsearch, etc.
C'est une distinction très importante car, contrairement aux déploiements, StatefulSet gère la réplication des pods et leur mise à l'échelle tout en veillant à ce que les lectures et les écritures de la base de données soient synchronisées afin d'éviter les incohérences de données.
Cependant, déployer des applications de base de données en utilisant StatefulSet dans un cluster Kubernetes peut être fastidieux, c'est donc plus difficile que de travailler avec des déploiements où vous n'avez pas tous ces défis. C'est pourquoi il est également courant d'héberger des applications de base de données en dehors du cluster Kubernetes et de n'avoir que des déploiements ou des applications sans état à l'intérieur du cluster Kubernetes qui se répliquent et se mettent à l'échelle sans problème, et qui communiquent avec la base de données externe.
Maintenant que nous avons deux répliques de mon pod d'application et deux répliques de la base de données, et qu'ils sont tous deux équilibrés en charge, notre configuration est plus robuste, ce qui signifie que même si le premier nœud était redémarré ou s'est crashé et que rien ne pouvait fonctionner dessus, nous aurions toujours un second nœud avec des pods d'application et de base de données en cours d'exécution, et l'application resterait accessible par l'utilisateur jusqu'à ce que ces deux répliques soient recréées pour éviter une interruption de service.
Exemple
Imaginons que nous sommes dans une entreprise nommée "MonEntreprise" qui développe une application web nommée "MonApp". Nous voulons déployer cette application sur un cluster Kubernetes et garantir que les données de l'application soient persistées même si les pods sont redémarrés ou supprimés.
Pour ce faire, nous utiliserons un déploiement pour gérer la mise à l'échelle de l'application et un StatefulSet pour garantir la persistance des données. Voici un exemple de YAML pour déployer notre application :
apiVersion: apps/v1
kind: Deployment
metadata:
name: monapp-deployment
spec:
replicas: 3
selector:
matchLabels:
app: monapp
template:
metadata:
labels:
app: monapp
spec:
containers:
- name: monapp-container
image: monentreprise/monapp:v1
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: monapp-statefulset
spec:
serviceName: monapp-service
replicas: 3
selector:
matchLabels:
app: monapp
template:
metadata:
labels:
app: monapp
spec:
containers:
- name: monapp-container
image: monentreprise/monapp:v1
ports:
- containerPort: 80
volumeMounts:
- name: monapp-data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: monapp-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
Dans ce YAML, nous définissons d'abord un déploiement nommé monapp-deployment qui comporte 3 répliques (pods) et qui utilise un conteneur basé sur l'image monentreprise/monapp:v1.
Nous utilisons également un StatefulSet nommé monapp-statefulset qui comporte également 3 répliques et utilise le même conteneur. Le StatefulSet utilise également un volume nommé monapp-data pour garantir la persistance des données.
Avec ce YAML, nous pouvons déployer notre application sur un cluster Kubernetes en utilisant la commande kubectl apply -f monapp-deployment.yaml. Le déploiement gérera la mise à l'échelle de l'application tandis que le StatefulSet garantira que les données.
Les DeamonSets VS le StatefulSets
Les DaemonSets sont un composant de Kubernetes qui permet de déployer des pods sur chaque noeud d'un cluster de manière durable. Les DaemonSets sont conçus pour des tâches telles que la surveillance du système, la collecte de métriques et la gestion des réseaux.
Les StatefulSets, quant à eux, sont conçus pour les applications qui nécessitent une gestion de l'état, telles que les bases de données. Les StatefulSets garantissent la synchronisation des lectures et des écritures de la base de données pour éviter les incohérences de données. De plus, ils prennent en charge la réplication et la mise à l'échelle des pods, tout en garantissant la persistance des données à travers les redémarrages et les erreurs.
En somme, les DaemonSets sont utilisés pour des tâches système et de fond de tâche, tandis que les StatefulSets sont utilisés pour les applications qui nécessitent une gestion de l'état et la persistance des données.
Pour résumer
Pour résumer, nous avons examiné les composants de Kubernetes les plus utilisés. Nous commençons avec les pods et les services pour communiquer entre les pods et le composant ingress qui est utilisé pour acheminer le trafic dans le cluster. Nous avons également examiné la configuration externe à l'aide de ConfigMap et de Secrets et la persistance des données à l'aide de volumes. Enfin, nous avons examiné les gabarits de pod avec des mécanismes de réplication tels que les déploiements et les stateful sets, où le stateful set est utilisé spécifiquement pour les applications stateful telles que les bases de données. En utilisant simplement ces composants de base, vous pouvez construire des clusters Kubernetes très puissants.



